Hello,
long time no see :)
We obviously have a lot to talk about when it comes to the game changes we recently did, or plan to do, but we don't want to share any of it yet.
Yet, there is currently a topic very relevant to us and we can share it without revealing any specific changes to the game. Today's post will be quite technical and related to programming, so if you just came for the game news, you can safely skip this one.
Now that there are only developers here, I can share my new discovery of Uncle Bob and his really nice explanation of some of the fundamental principles related to programming project management, and more. If you have 8.5 free hours on your hands, I propose you watch it, as there will be some references to what he mentions later on.
My general thought was, that we maintain the quality of the code to be quite high, and we have a reasonably good work methodology. But we were the victims of selective blindness in many places actually. It is interesting, how some pieces code were just good from start and stayed pretty good throughout all the years, even when it was expanded a lot... and some of the code just deteriorated heavily.
And the answer is explained with the metaphor of the wax foundation.
What is a wax foundation and how is it related to programming you might ask? My grandfather was a very enthusiastic bee-keeper. My childhood was spent in our garden, where you had to be careful where you step, where you sit down, and you could never leave anything sweet just laying around, because you would find a big pile of bees on top of it quite soon. I had to help him and learn about the bees from time to time, which I honestly hated, because I knew that I will never have any bees of my own. But he was right about one thing, everything you learn will be useful to you in one way or another.
One of the jobs you do around bees, is that when the honey is taken away from the bees, you put the wax foundation in the hive, which looks like this:

Its primary function is that the bees build their tiles evenly and quite fast, as it is just natural to follow the optimised structure that is already there. And this is exactly what happens with code that has a good and expandable design from the start.
On the other hand, there is code that either had a lazy original design, or it was never expected to grow so much in complexity, and each of the changes were just a small addition to the mess. Eventually we got used to the idea that this part of the code is just hell, and that making small changes is annoying. This implies that we just don't like this part of the code, and we want to spend as little time as possible working with it. And the result is that the problem is slowly spiralling out of control.
When I took the Uncle Bob glasses and started looking around, I quickly identified several problematic places like this. It is not a coincidence, that these places were eating away an disproportionately large amount of the dev time, not only because making changes is hard, but because they are full of regression bugs and generally are a never-ending source of problems.
This is the beautiful thing about having a company that isn't on the stock market. Imagine you have a company that goes slower and slower every quarter, and then you confront the shareholders with the statement, that the way to solve it, is to do absolutely no new features for a quarter or two, refactor the code, learn new methodologies etc. I doubt that the shareholders would allow that. Luckily, we don't have any shareholders, and we understand the vital importance of this investment in the long run. Not only in the project, but also in our skill and knowledge, so we do better next time.
This is the timeline of the lines of code in Factorio

It would look pretty reasonable if there was the same amount of people working from start to finish, but it is not. It was just me at the very start, and now there are 9 programmers. It could be explained by the game getting bigger and growing a lot of interconnected mechanics, which is harder to maintain. Or it could also mean that the density of the code improved so much. Both of these are not enough explain why having more programmers doesn't result in faster development.
This indicates that the problems Uncle Bob describes are relevant to us, and the solution is actually to improve the way we develop rather than just scaling the amount of people. Once we have a nice clean foundation, then hiring new programmers and getting them up to speed with the code will be much faster.
Let me now explain a few typical examples of the problems we had, and how we proceeded to fix them:
We wrote a lot about the GUI (for example FFF-216) and how we iteratively raised the bar of what we find acceptable both from both the user and programmer perspective. The common takeaways from the FFF and from the coding was, that we always underestimated how complicated GUI logic/styles/layouting etc. can become. This implies that improving the way the GUI is written has large potential gains.
We are happy with the way the GUI objects are structured and laid out since the 0.17 update. But codewise, it still feels much more bloaty than it should be. The main problem was the amount of places you needed to touch to add some interactive element. Let me show you an example, a simple button used to reset presets in the map generator window.
In the class header:
class MapGeneratorGui
{
...
We had a button object definition
... IconButton resetPresetButton; ...
In the constructor of MapGenerator, we needed to construct the button with parameters
...
, resetPresetButton(&global->utilitySprites->reset, // normal
&global->utilitySprites->reset, // hovered
&global->utilitySprites->resetWhite, // disabled
global->style->toolButtonRed())
...
We needed to register as a listener of that button
... this->resetPresetButton.addActionListener(this); ...
Then, we needed to override the method of the ActionListener in our MapGeneratorClass, so we could listen to the click actions.
... void onMouseClick(const agui::MouseEvent& event) override; ...
And finally, we could implement the method, where we if/else through the elements we care about, to do the actual logic
void MapGeneratorGui::onMouseClick(const agui::MouseEvent& event)
{
if (event.getSourceWidget() == &this->resetPresetButton)
this->onResetSettings();
else if (event.getSourceWidget() == &this->randomizeSeedButton)
this->randomizeSeed();
...
This is way too much boilerplate for one button with one simple action. We had over 500 places where we registered actionListeners in the code, so imagine the amount of bloat.
We kind of noticed, that when we use lambdas to signal callbacks and similar things in the GUI, it tends to be much more pleasant to use. So what if we made it the primary way to do the GUI?
We decided to completely rewrite the way it works, so instead of adding listeners and the filtering from the event catching functions, we can just specify:
this->resetPresetButton.onClick(this, [this]{ this->onResetSettings(); });
Which is a big improvement already, as adding and maintaining the new logic only requires you to look at one place instead of several, and it makes it generally more readable and less prone to errors.
And since we don't need to hold the pointer object for comparisons, we can completely remove its definition from the class, and make it anonymous on many places in this fashion:
*this << agui::iconButton(&global->utilitySprites->reset,
global->style->toolButtonRed(),
this, [this]{ this->resetPreset(); })
Rewriting all the GUI internals (again) was a big task, but in the end it really felt to be well worth it, as now I can't imagine how we could stand doing it the old way. It also resulted in several thousands of lines of code being removed.
The only way to go fast is to go well!
There are several main goals to pursue when you try to make the code cleaner. Removing code duplication is the first and biggest priority. It is reasonably easy to solve when the code isn't structured well, functions are too long, or names are weird, but if you have 5 versions of the same pile of code with slight changes here and there, it is the worst beast. It is just a question of time, until bugfixes/changes are only applied to some variants, and it becomes less and less obvious whether the differences between the variants are intended or circumstantial.
The manual building logic is a monster, because of all the things it supports already:
Then, all of this logic needs to be multiplied by 2 (when you are lazy and copy paste), as you can have normal building and ghost building.
And then, you multiply this whole code abomination by 2 again. Why? Because we also need to do all this logic in the latency hiding mode. Sounds bad already, but it isn't all of it, since this logic was continually being patched and touched by different people throughout history, the core of the code was a crazy long method with the code looking like the horizon mentioned by Uncle Bob.
Now imagine that you need to change something about this code, especially when you take into consideration, that the code naturally had many corner cases wrong, or fixed only in some variant of the code. This is a great example of how lazy long-term design leads to poor productivity.
Long story short, this was approached like a hobby side project of mine that took weeks to be finished, but in the end, all the duplications were merged, the code is well structured and fully tested. Managing the code requires a small fraction of the time compared to the previous state, because the reader is not required to read a huge pile of code just to get the big picture and to be able to change anything.
This reminds me a quote from Lou after a similar kind of refactoring: "Once we are done with this, it will be actually a pleasure to add stuff to this code.". Isn't it beautiful? It is not only more efficient and less buggy, it is also more fun to work with, and working on something enjoyable tends to go faster regardless of other aspects.
The only way to go fast is to go well!
No, we obviously didn't get to this point without automated tests, and we mentioned them several times already (FFF-29, FFF-62, FFF-288, and more). We try to continuously raise the bar of what code areas are covered by tests, and this lead us to cover yet another area, the GUI. This aligns with the ever repeating underestimation of the amount of engineering care the GUI needs. Having it not tested at all is part of this underestimation, how many times it happened, that we made a release, and it just crashed on something stupid simple in a GUI, just because we didn't have a test that would click the buttons. And in the end, it proved to not be hard at all to automate the GUI tests.
We just have a mode in which the testing environment is created with GUI (even when tests are run without graphics). We declared some helper methods, that allow a very simple definition of where we want the cursor to move, or what we want to click, like this:
TEST(ClearQuickbarFilter)
{
TestScenarioGui scenario;
scenario.getPlayer()->quickBar[0].setID(ItemFilter("iron-plate"));
CHECK_EQUAL(scenario.player()->getQuickBar()[0].getFilter(), ItemFilter("iron-plate"));
scenario.click(scenario.gameView->getQuickBarGui()->getSlot(ItemStackLocation(QuickBar::mainInventoryIndex, 0)),
global->controlSettings->toggleFilter);
CHECK_EQUAL(scenario.player()->getQuickBar()[0].getFilter(), ItemFilter());
}
The clicking method is then calling the low level events of input, so all layers of event processing and GUI logic are tested. This is an example of end-to-end test, which is a controversial topic, because some "schools" of test methodology say, that everything should be tested separately, so in this case, we should theoretically test only, that clicking the button first, which creates an InputAction to be processed, and then, have an independent test of the InputAction working properly. I like this approach in some cases, but most of the time I really like that I can penetrate all layers of the logic with only a few lines of code. (more in the Test dependencies part)
The only way to go fast is to go well!
I have to admit, that I didn't know what TDD really was until recently. I thought that it is some nonsense, because it sounds really impractical and unrealistic to first write all the tests for some feature (without the ability to try it or even compile it), and then try to implement something that satisfies it.
But that is not TDD, and it had to be shown to me in a "for dummies" way for me to realize how wrong I was.
TDD actually is the constant fast switching between extending the tests and making them pass continuously. So as you write tests, you write code to satisfy them basically at the same time. This allows you to instantly test what you write, and mainly use tests as specification of what the code should actually do, which guides the thought process to make you think about where you are headed to, and to write code that is more structured and testable from the very beginning.
So after the "AHA" moment of realizing what TDD really is, I started to be instant fan. I'm now putting a lot of effort to try to follow the TDD methodology as much as possible, and to force it on others in the team as well. It feels slower, to write tests even for simple pieces of logic that just bound to be right, but the test proved me wrong several times already, and prevented annoying low-level debugging sessions in the near future.
The only way to go fast is to go well!
This is a continuation of the test dependency topic from GUI tests.

If tests should be truly independent, test C, should have some mocks of A and B, so the test of C is independent of the system A + B working correctly. The consensus seems to be, that this leads to more independent design etc.
This might be applicable in a lot of cases, but I believe that trying to have this approach everywhere is close to impossible, and it would lead to a lot of clutter and I'm not the only one having problem with this.
For example, lets say that we have a test of electric poles connecting properly on the map. But I can hardly test it when I don't know that searching for entities on the map works properly.
My conclusion is, that having dependencies like this is fine, as long as the dependencies are also tested, but the problem comes when you break something and a lot of tests start to fail suddenly. When you do small changes the yes/no indication of tests is enough, but it isn't always an option, especially when you refactor some internal structure, in which case you kind of expect to break a lot of stuff, and you need to have a way to fix them step by step once it can compile again.
If the tests don't have any special structure, the situation when 100 tests all fail at the same time is very unfortunate, all you are left with is to try to pick some test semi-randomly, and start debugging it. But it is really misleading when some complicated test case fails in the middle, and you spend a long time debugging it, only to realise that it is some very simple low level bug that is causing the failure.
The goal is pretty easy, I want to be given the most simple fail case of my change.
For this, I implemented a simple test dependency system. The tests are executed and listed in a way, that when you get to debug and check a test, you know that all of its dependencies are already working correctly. I tried to search if others use the dependencies as well, and how they do it, and I surprisingly didn't find anything.
This is an example of a test dependency graph related to electric poles:

I built and used this structure when refactoring away the duplication of ghost/real poles connection logic and it certainly sped up the process of making it work properly, and I'm confident that this is the way to structure test for us in the foreseeable future. Not only it makes test results more useful, but it forces us to split test suites into smaller more-specialised units, which certainly help as well.
The only way to go fast is to go well!
When Boskid joined the team as the QA guy, one of his main roles was making sure that any discovered bug is first covered by a test before it gets actually fixed, and generally improving our code test coverage. This made the releases much more confident, and we had less regression bugs, which directly transitions into long-term efficiency. I strongly believe that this clearly indicates and supports what Uncle bob is saying. Working with tests feels slower but it is actually faster.
Test coverage is an indicator of which parts of the code are executed when the application runs (which usually means running the tests in this context). I never used a tool to measure test coverage before, but since it was one of the topics Uncle Bob talked about, I tried to use it for the first time. I found a tool that works only on Windows, but requires the least amount of setup, which is OpenCppCoverage, which provides an HTML output like this:
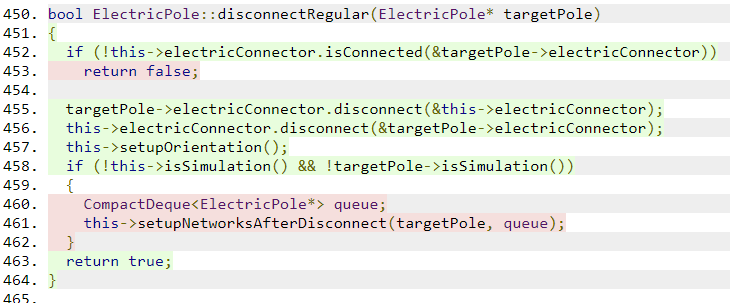
It is immediately visible, that both of the conditional commands are not triggered in tests. It basically means that either the code just isn't tested, so it should be covered, or it's dead code, so it should be removed. I'm quite confident (again), that using this can help us a lot to write clean high quality code.
The only way to go fast is to go well!
The only way to go fast is to go well!
If you are moved by this, if your emotion when you read this is, "I wish my boss had these priorities". Consider applying for a job at Wube!